Artificial Intelligence (AI) models may appear intelligent, but their “learning” is actually the result of a highly structured and repetitive process known as a training loop. This process is at the heart of machine learning and deep learning systems. Without it, models would remain static and unable to improve their performance.
In this article, we’ll go deeper into how training loops work, why they are essential, and how they enable AI models to learn from data step by step.
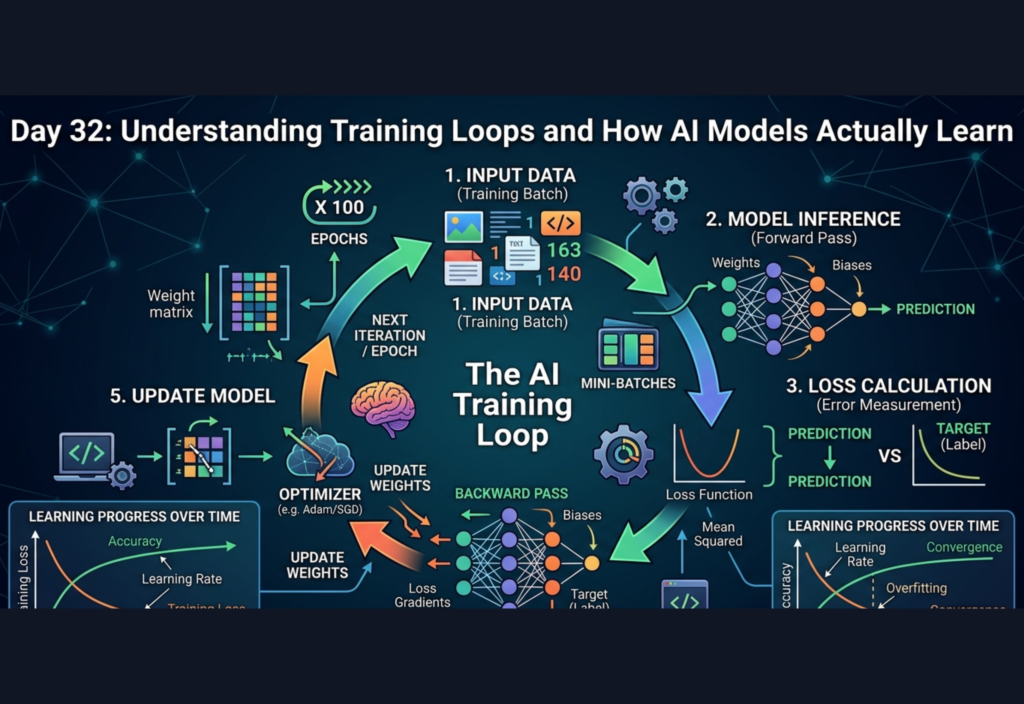
What is a Training Loop?
A training loop is a repeated cycle used to train an AI model on data. During each cycle, the model processes input data, makes predictions, evaluates errors, and updates its internal parameters.
The goal of this loop is simple:
Minimize the difference between the model’s predictions and the actual correct outputs.
This process repeats many times until the model becomes accurate enough.
Core Idea Behind AI Learning
AI models do not “understand” data like humans. Instead, they learn by:
- Identifying patterns in data
- Adjusting numerical parameters (weights and biases)
- Reducing prediction errors over time
Each iteration of the training loop slightly improves the model.
Think of it like practicing a skill repeatedly—each attempt refines performance.
Components of a Training Loop
A typical training loop consists of several important elements:
1. Dataset
The dataset contains examples used for training. Each example usually includes:
- Input (features)
- Output (labels or targets)
Example:
- Input: Image of a cat
- Output: “Cat”
2. Model
The model is a mathematical function (often a neural network) that maps inputs to outputs.
It contains:
- Layers
- Weights
- Biases
These parameters are what the model learns during training.
3. Forward Pass
In the forward pass:
- Input data is passed through the model
- The model produces a prediction
This is the model’s current “guess.”
4. Loss Function
The loss function measures how far the prediction is from the actual answer.
- High loss → poor prediction
- Low loss → accurate prediction
Common loss functions include:
- Mean Squared Error (MSE)
- Cross-Entropy Loss
The loss function acts as a feedback signal.
5. Backpropagation
Backpropagation is the process of calculating how much each parameter contributed to the error.
It computes gradients using calculus and helps determine:
- Which weights need adjustment
- In what direction they should be updated
6. Optimizer
The optimizer updates the model’s parameters using gradients.
Popular optimizers include:
- Stochastic Gradient Descent (SGD)
- Adam
The optimizer’s job is to reduce the loss step by step.
Step-by-Step Training Loop Process
A single iteration of training typically follows this sequence:
Step 1: Load Data
A batch of data is selected from the dataset.
Step 2: Forward Pass
The model processes the input and generates predictions.
Step 3: Compute Loss
The predictions are compared with the true labels to calculate error.
Step 4: Backward Pass
Gradients are computed to understand how to adjust weights.
Step 5: Update Weights
The optimizer modifies the parameters to reduce loss.
Step 6: Repeat
The loop continues for many iterations.
Epochs, Batches, and Iterations
To understand training loops properly, three important terms must be clear:
Epoch
One complete pass through the entire dataset.
Batch
A subset of the dataset processed at one time.
Iteration
One update step using one batch.
Example:
- Dataset size = 1000 samples
- Batch size = 100 samples
- Iterations per epoch = 10
Why Training Requires Multiple Epochs
A single pass through data is not enough for learning. Models need multiple epochs because:
- Initial predictions are random
- Errors are large at the beginning
- Gradual updates refine the model
With each epoch:
- Loss decreases
- Accuracy improves
- Predictions become more reliable
Learning Through Error Correction
The key principle behind training loops is error correction.
The model:
- Makes a prediction
- Compares it with the correct answer
- Measures the error
- Adjusts itself to reduce that error
Over time, this repeated correction leads to learning.
Intuition: How It Feels Like Learning
Imagine teaching a child to recognize animals:
- First attempt: guesses incorrectly
- You correct them
- Next attempt: slightly better
- After many repetitions: correct identification
AI training works similarly, but instead of verbal feedback, it uses mathematical loss functions and gradients.
Challenges in Training Loops
1. Overfitting
The model performs very well on training data but poorly on new, unseen data.
2. Underfitting
The model fails to capture patterns in the data and performs poorly overall.
3. Gradient Issues
- Vanishing gradients slow down learning
- Exploding gradients cause instability
4. Computation Cost
Training large models requires:
- High processing power
- GPUs/TPUs
- Significant time
Importance of Hyperparameters
Training loops are influenced by hyperparameters such as:
- Learning rate
- Batch size
- Number of epochs
These are not learned by the model but must be set by the developer.
For example:
- A high learning rate may cause instability
- A low learning rate may slow down training
Real-World Example of a Training Loop
Consider training a text prediction model:
Input:
“Machine learning is”
Target Output:
“powerful”
If the model predicts:
“difficult”
Then:
- Loss is calculated
- Backpropagation identifies errors
- Weights are updated
- Next prediction becomes closer to “powerful”
Repeating this process across millions of examples enables the model to generate coherent text.
Visualization of the Training Loop
A simplified flow looks like this:
- Input Data
- Model Prediction
- Loss Calculation
- Backpropagation
- Parameter Update
- Repeat for many batches and epochs
This loop is the engine behind learning.
Why Training Loops Work
Training loops work because of optimization:
- The model starts with random parameters
- Each iteration adjusts parameters slightly
- The loss function guides improvements
- Over time, the model converges toward an optimal solution
This process is essentially a guided search through a large parameter space.
Conclusion
Training loops are the foundation of how AI models learn. They transform raw data into intelligence through repetition, error correction, and optimization.
By understanding the training loop, you gain insight into:
- How models improve over time
- Why large datasets are important
- How predictions become accurate
- What happens behind the scenes in AI systems
In simple terms, AI learning is not instant—it is the result of thousands or even millions of small adjustments made through structured training loops.

